A general introduction of Dask
Python is now the most popular programming language for data scientists and machine learning engineers. Python’s success can be in part credited to its efficient computational libraries such as NumPy, Pandas, and Scikit-Learn. However, these powerful tools are mostly designed to run on a single machine. In a production machine learning system, such tools are not likely to scale well, since large datasets usually require computation power and memory from more than one machine. Very likely, we will run into memory problems (e.g., insufficient RAM) if we load our large dataset into one single machine. Fortunately, Dask was developed to solve this problem and scale our ML system to distributed clusters of machines.
First released in 2014, Dask is a flexible library for parallel computing in Python. It’s mainly composed of two parts:
1. Dynamic task scheduling optimized for computation. This means your code won’t start work until you call certain function to trigger them, and we’ll explain it in later parts.
2. Extending Python Data Science libraries like NumPy, Pandas to larger-than-memory or distributed environments. It basically enables us to run the same code including Numpy and Pandas with much faster way.
In this blog, we’ll explore on how Dask handles big data and display how it works by using it on a movie recommendation system.
Overview of Dask
For ML developers in Python, Dask has a very familiar API. Dask integrates extremely well with the tools mentioned earlier (e.g. NumPy, Pandas) so that Dask essentially shares the same API as them. As a result, ML developers will pick up Dask immediately and use it to solve problems on a larger scale. The code snippet below shows how Dask mimics Pandas and NumPy.

When dealing with large datasets, it is likely that they cannot fit in memory on a single machine. In this scenario, we can use Dask to create a cluster of machines that together have enough memory to hold large datasets. For example, Dask arrays coordinate many NumPy arrays, where those NumPy arrays can be on different machines. Similarly, Dask DataFrames coordinate many Pandas DataFrames. See below for illustration.


These DataFrames and Arrays are distributed into different machines, and Dask will perform parallel computation which significantly boost the computation speed.
At the same time, Dask can also improve the performance on a single machine by leveraging multi-core on parallel computation. The advantage for such operation is an easy setup and no restriction on the environment. Even for beginners, you can simply try on Dask by installing Anaconda on your computer and manipulate with datasets over 100GB even if your computer has relatively low memory.
Now we see how Dask improves performance in both clusters and single machine, let’s try it on our movie recommendation system.
Dask API
We will demonstrate how to use Dask to create a single machine scheduler that works with multiple processes/threads. Unfortunately, we are not able to demonstrate Dask in a distributed systems setting, because we are unable to create multiple VMs on AWS Education (On regular AWS, we can easily create multiple VMs, but AWS Education seems to have some limitations of that). Still, Dask with multiple processes on a single machine is still very effective as it utilizes all the cores on the machine. This is expected to be 4 times faster than Pandas or Numpy API on a 4-core machine. In a production machine learning system, multi-core computation is largely favored over single-core computation.
To utilize multiple cores, we can create a pool of processes to execute the Dask commands.

Dask supports a large subset of Pandas API. As we mentioned, a Dask DataFrame is just a large parallel DataFrame composed of many smaller Pandas DataFrames. In the scenario of movie streaming, we set up a single-machine scheduler by “import dask.dataframe as dd” and then simply apply methods similar to Pandas/Numpy API on our movie rating file. Below are examples of our simple manipulation of data using Dask:

Note that Dask DataFrames are lazy, which means it won’t immediately perform the computation work until we trigger it. As a result, when we print the DataFrame in the image above, no data is actually shown. Instead, we only get a table showing the data type of each column.
To show the result as Pandas DataFrames, we can simply trigger the function by calling .compute(). Like the sample below, when we try to compute the average over “age” column in DataFrame, it returns a Dask DataFrame scalar series object. For a Dask DataFrame, the method .mean() only provides a “recipe” to it. It tells Dask DataFrame how to do the work, but Dask DataFrame won’t implement it.

When we call .compute() to the same command, it starts the computation and returns the average value of age column.

As we discussed before, Dask supports most of Pandas API, which enables us to manipulate data in a really familiar way. For instance, we can check the size of DataFrame, downsample it and only keep unique user_id with the same Pandas methods, all we need to do is to call .compute() to do the work.
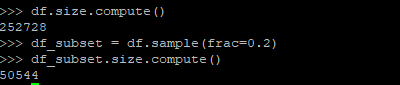

Besides Pandas, Dask also provides its equivalent to NumPy. A Dask Array is similar to NumPy, but operations on Dask array could utilize all the cores on the machine.

Movie Recommendation Case
Now we understand the basic API for Dask, let’s try it on our movie recommendation data. We are currently using data of movies that users rated or watched to make recommendations to them. The database we used for training movie recommendation is enormous as we kept receiving new data when users watched or rated on movies. As a result, the current database has over 2.6 million records, including the rated movies from Jan 23rd to Feb 19th in 2021.
We first initialize our movie rating file with over 2.6 million records of ratings and user file with about 1 million user information.

We import Dask DataFrame as “pd”. Note that normally we would call Dask DataFrame as “dd”, but here we call it as “pd” to show how it uses the same Pandas API to do the same work.

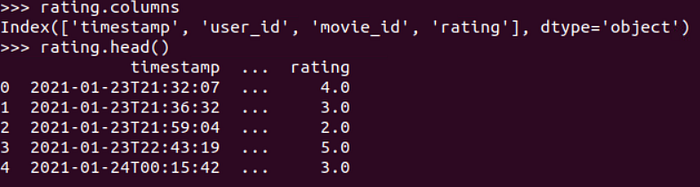
We use .read_csv() function to load the movie rating file as a Dask DataFrame and shows the result.

It includes 4 columns: timestamp, user_id, movie_id and rating.
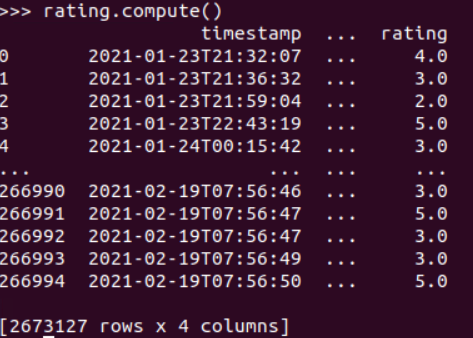
Applying .compute() to display the DataFrame, it shows the database includes 2, 673, 127 rows of rating records.
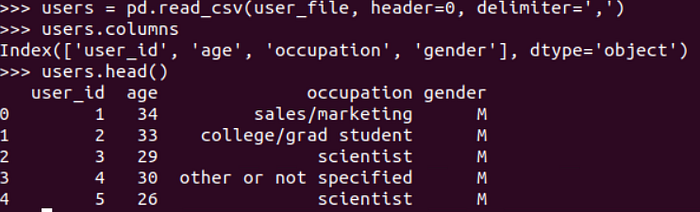
We apply the similar process to user file, and the result is shown as below.
The idea behind our recommendations is for similar users, we believe they are going to watch similar movies. To do further work with this idea, we need to merge two DataFrames based on user_id. We simply apply .merge() on two DataFrames, setting “on” parameter to “user_id”, the result is shown as below.
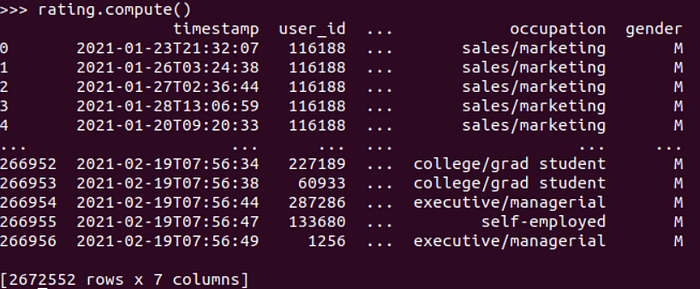
We get a new DataFrame 2, 672, 552 rows and 7 columns. We can then use this DataFrame for further training.
For people used Pandas and NumPy before, it will be really convenient for you to try Dask. All you need to do is to change “import pandas” and “import numpy” to “import dask” in your codes and then you can enjoy the performance boost from parallel computing.
The preprocess of our database may seem fairly easy, but database is actually quite large for Pandas DataFrame. In fact, when we applied the old method that used Pandas DataFrame for processing rated movies and users information, it took about 5.17 seconds to just load and merge 2 DataFrames. However, when we switched to Dask by simply changing “import pandas” to “import dask.dataframe” and rerun the code, the whole process only took 0.03 seconds.
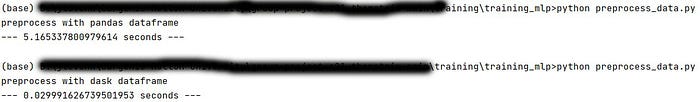
Imagine for a system like Netflix with millions of users, the database could be even larger. With Dask, it enables us to work on big dataset even on single machine.
Dask Strength & Limitations
From examples above, we can see Dask provides a lot of powerful features that help us with handling big data. It allows us to distribute work on thousands of clusters, and also improve the performance on single machine by using multi-cores. It’s really user-friendly for Python users since it’s syntax is pretty much the same. By simply replacing NumPy and Pandas to Dask Array and DataFrame, we will be able to take advantage of Dask’s parallel computing and run programs in a much faster way.
Though Dask provides really powerful performance boost for handling big data and wonderful integration to python, there are certain limitations to it:
- When there are multiple tasks for Dask to run, it runs in a first-come-first-served mode and assign the tasks to workers. While it usually makes the right decision, non-optimal situations can occur for multi-machine mode.
- We mentioned that Dask integrates Pandas and NumPy API and is really easy for Python users to work on it. Still, it doesn’t support all the methods in these libraries. For functions beyond Dask DataFrame, we need other functions to replace them.
- Since Dask workers are just Python processes, it inherits all the limitations from Python.
That’s all for our introduction of Dask. We hope you enjoy it and learn more about Dask after reading it!
